
→ →
Модуль арифметики над данными позволяет проводить произвольные операции над точками отдельного поля данных или соответствующими точками нескольких полей данных (на текущий момент до восьми). И, хотя это не является его главным предназначением, он может использоваться как калькулятор с непосредственным расчётом выражений если ввести простое арифметическое выражение. Синтаксис выражений описан в разделе Выражения.
Выражение может содержать следующие переменные, соответствующие значениям отдельных входных изображений:
| Переменная | Описание |
|---|---|
d1, …, d8 | Значение данных в точке. Значение записывается в основных физических единицах, например, для высоты в 233 нм, значение d1 равно 2.33e-7. |
m1, …, m8 | Значение маски в точке. Значение маски равно либо 0 (для немаскированных точек) либо 1 (для точек под маской). Переменные маски могут использоваться и если маска не задана, значение равно 0 во всех точках в этом случае. |
bx1, …, bx8 | Производная по горизонтали в точке. Снова значение в физических единицах. Производная считается как стандартная симметричная производная, кроме точек на границе, где берётся производная только с одной стороны. |
by1, …, by8 | Производная по вертикали в точке, определяется так же, как и производная по горизонтали. |
x | Горизонтальная координата точки (в физических единицах). Одинакова во всех полях из-за требования совместимости (см. ниже). |
y | Вертикальная координата точки (в физических единицах). Одинакова во всех полях из-за требования совместимости (см. ниже). |
В дополнение определяется константа π, которую можно набирать либо как π, либо как pi.
Все изображения, которые реально используются в выражении должны быть совместимы. Это означает, что их размеры (как физические, так и в пикселях) должны быть идентичны. Другие поля данных (те, что не входят в выражения) ни на что не влияют. Результат всегда помещается в созданное заново изображение в текущем открытом файле (который может отличаться от файлов, содержащих все операнды).
Поскольку модуль расчёта не может автоматически вывести правильные физические единицы измерения результата, единицы должны быть явно указаны. Это можно сделать двумя путями: или выбрав поле данных с теми же единицами значений, что должны быть у результата, или выбрав опцию Задать единицы и введя единицы вручную.
Следующая таблица содержит несколько простых примеров выражений:
| Выражение | Значение |
|---|---|
-d1 | Инвертирует значение. Результат очень похож на Инвертировать значение, за исключением того, что последнее инвертирует значения относительно среднего в то время, как здесь мы просто меняем знак у значений, |
(d1 - d2)^2 | Квадрат разницы между двумя полями данных. |
d1 + m1*1e-8 | Модификация значений под маской. Конкретно в этом случае значение 10−8 добавилось ко всем точкам под маской. |
d1*m3 + d2*(1-m3) | Комбинация двух полей данных. Точки берутся либо из поля 1, либо из 2, в соответствии с маской, заданной на поле 3. |
В режиме калькулятора выражение вычисляется сразу по мере его ввода и результат показывается под полем ввода выражения. Не требуется совершать специальных действий чтобы переключаться между выражениями над изображениями и калькулятором: выражения, содержащие только численные величины рассчитываются сразу, выражения, содержащие изображения используются чтобы рассчитать новое изображение. Изображение предпросмотра, показывающее результат операции с изображениями, не обновляется сразу следом за набором выражения; его можно обновить или нажатием на кнопку или нажатием Enter в поле ввода выражения.
→ →
Нередко может быть полезно сравнить соответствующие линии скана на разных изображениях, в частности на прямом и обратном проходе. Это можно сделать используя опцию Множественный профиль и выбирая два изображения как 1 и 2 в списке Изображения. Выбранные линии скана будут показаны на изображении. Эту линию можно перемещать по изображению с помощью мыши или номер линиии скана можно ввести численно используя опцию Линия скана.
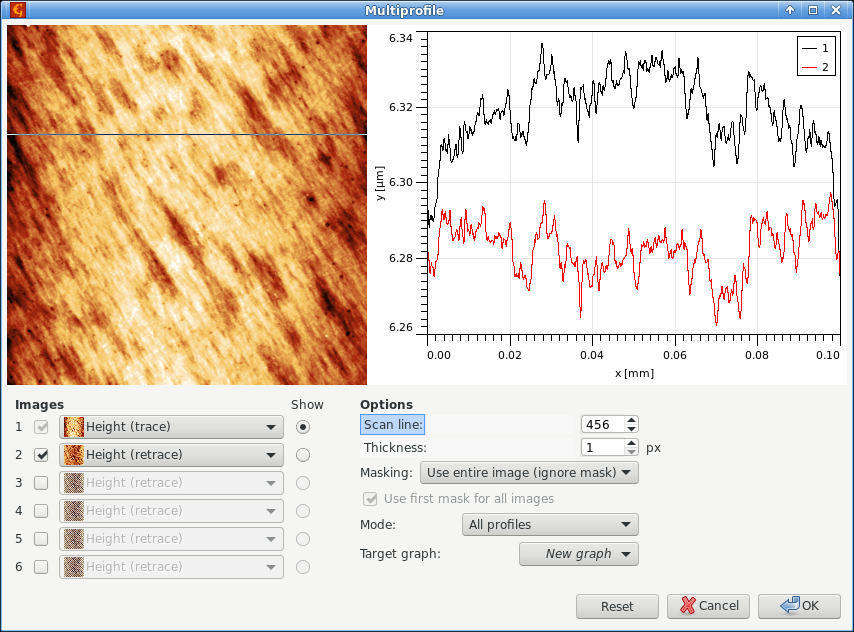
Основной тип использования модуля множественных профилей, где изображения прямого и обратного прохода сканирования выбраны в качестве 1 и 2 и соответствующая пара профилей показывается на графике.
Профили можно читать одновременно с нескольких изображений вплоть до шести. Можно включать и выключать отдельные изображения используя чекбоксы рядом с номером изображения. Любое из включенных изображений может показываться в маленьком окне предпросмотра, что управляется выбором их используя опцию Показать.
Поскольку график показывает взаимно соответствующие профили, все изображения должны иметь одинаковые размеры в пикселях и реальные, и должны представлять одну и ту же физическую величину. Изображение 1 рассматривается как особое в этом отношении. Оно не может быть не выбрано и оно задаёт разрешение и другие свойства. Другими словами, все остальные изображения должны быть совместимы с изображением 1.
Опции в нижней правой части окна включают стандартное управление шириной профиля (усреднением поперёк линии профиля), которая работает так же, как для обычного инструмента получения профиля, опции работы с маской и график для извлечения профилей. Маски могут быть как взяты из соответствующих изображений, так и маска первого изображения может использоваться для всех, в том случае, если опция Использовать первую маску для всех изображений включена.
Вместо того, чтобы извлекать отдельные профили, модуль может также рассчитывать простую статистику и строить сводные кривые - среднюю кривую с верхними и нижними границами. Это управляется опцией Режим.

→ →
Встраивание вставляет фрагмент, изображение с более высоким разрешением, внутрь более крупного изображения. Изображение, на котором была запущена функция формирует большое, базовое изображение.
Положение фрагмента может быть задано вручную на большом изображении с помощью мыши. Кнопка может быть затем использована для получения точных координат в окрестности текущей позиции, которые дают максимум корреляции между фрагментом и большим изображением. Или наиболее подходящее положение может быть найдено на всём изображении с помощью кнопки .
Следует отметить, что корреляционный поиск не чувствителен к масштабу значений и смещений, следовательно, автоматический поиск соответствия основан исключительно на свойствах данных, абсолютные значения высоты не играют значения.
Разрешение результата контролирует размер и разрешение результирующего изображения:
- Увеличить разрешение большого изображения
- Разрешение результата определяется разрешением встраиваемого фрагмента. Следовательно, масштаб большого изображения увеличивается.
- Снизить разрешение фрагмента
- Разрешение результата определяется разрешением большого изображения. Масштаб фрагмента уменьшается.
Выравнивание фрагмента выбирает преобразование значений z фрагмента:
- Нет
- Подстройка значений z не производится.
- Среднее значение
- Все значения изображения фрагмента сдвигаются на постоянную величину так, чтобы его среднее значение соответствовало среднему значению соответствующей области большого изображения.

→ →
Изображения, которые формируют части большего изображения, могут быть объединены вместе с помощью команды "Объединить." Изображение, на котором была запущена эта функция формирует базовое изображение, изображение, выбранное с помощью Объединить с, представляет второй операнд. Сторона базового изображения к которой будет присоединено второе управляется с помощью выпадающего меню Поместить второй операнд.
Если изображения идеально соответствуют друг другу, они могут просто совмещены сторонами без подстройки. Этот вариант выбирается опцией Нет в управляющем выравниванием элементе Выровнять второй операнд.
Однако, обычно необходимы подстройки. Если изображения имеют одинаковый размер и выровнены в направлении, перпендикулярном к направлению слияния, единственной степенью свободы будет возможное перекрытие. В данном случае может использоваться метод выравнивания объединение. В отличие от поиска корреляции, описанного ниже, сопоставляются абсолютные значения данных. Это делает данную опцию подходящей даже для слабо меняющихся изображений если их абсолютные значения высоты измерены точно.
Опция Корреляция выбирает автоматическое выравнивание с помощью основанного на корреляции поиска наилучшего соответствия. Поиск производится как вдоль направления, параллельного присоединяемой стороне, так и в перпендикулярном ему. Если присутствует параллельный сдвиг, результат расширяется таким образом, чтобы в него полностью поместились оба изображения (отсутствующие значения заполняются значением фона).
Опция Режим границы полезна только в последнем случае неточно выровненных изображений. Она управляет тем, что будет с пересекающейся частью обоих изображений:
- Первый операнд
- Значения в пересекающихся областях берутся из первого, базового изображения.
- Второй операнд
- Значения в пересекающихся областях берутся из второго изображения.
- Сгладить
- Гладкий переход между первым и вторым изображением производится на пересекающейся области используя взвешенное среднее с подходящей функцией веса.

→ →
Сшивание является альтернативой модулю объединения изображений, описанному выше. Оно в основном полезно если точно известны относительные положения частей изображения поскольку позиции вводятся численною Они инициализируются с использованием смещений изображения, таким образом, если они правильны, сшитое изображение формируется автоматически. Кнопки для каждой части возвращают вручную измененные смещения к первоначальным.

→ →
С помощью этого модуля можно кадрировать два слегка сдвинутых друг относительно друга изображения одной и той же области (например, до и после какого-то воздействия), или, другими словами, обрезать непересекающиеся части возле границы изображений.
Общая область определяется корреляцией большего изображения с центральной частью меньшего. Разрешения обоих изображений (количество точек на единицу длины) должны быть одинаковы.
На текущий момент единственным параметром сейчас является Второй операнд - будет посчитана корреляция между ним и текущим активным изображением и оба изображения будут обрезаны чтобы удалить непересекающиеся области возле границы.

→ →
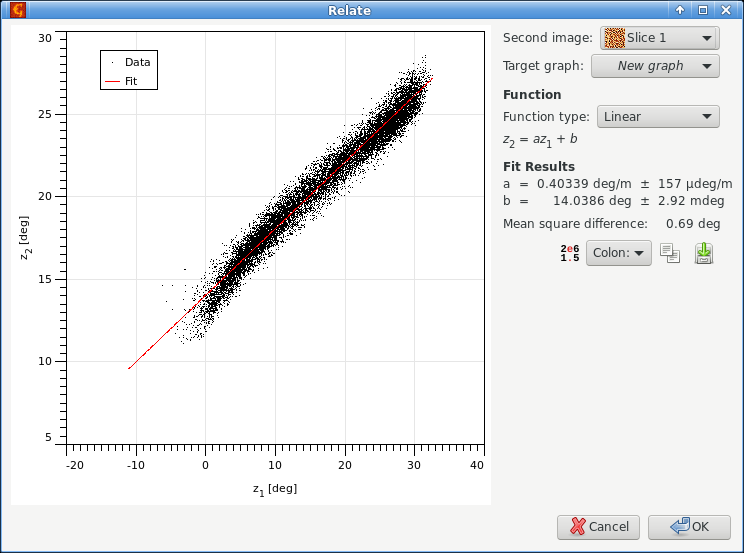
Когда данные двух изображений взаимосвязаны простым образом, например, они отличаются постоянным фактором калибровки, эта функция помогает найти такую взаимосвязь.
График в левой части показывает значения пикселей второго изображения (выбранного как Второе изображение) построенных как функцию соответствующих значений пикселей текущего изображения. Когда между данными существует простая взаимосвязь, все точки лежат на одной кривой. Следует отметить, что для больших изображений на графике строится только небольшая случайно выбранная подвыборка данных.
Некоторые простые взаимосвязи могут аппроксимировать данные точек, среди них есть пропорциональная, смещение, линейная или квадратная связь. Параметры аппроксимации рассчитываются моментально и показываются в таблице снизу, при этом строится соответствующий график взаимосвязи. Все значения пикселей используются для аппроксимации даже если показывается небольшое подмножество.
→ →
Модуль находит локальные корреляции между фрагментами двух различных изображений. В идеальном случае выводится сдвиг каждого пикселя первого изображения как показано на втором. Это можно использовать для определения локальных изменений на поверхности, которую сняли дважды (сдвиг может существовать, например, при какой-то деформации образца или неправильной работе микроскопа).
Для каждого пикселя первого операнда (текущего окна) модуль берёт его окрестность и ищет наилучшую корреляцию с вторым операндом внутри заданной области. Положение максимума корреляции используется для задания значения сдвига для вышеупомянутого пикселя первого операнда.
- Второй операнд
- Изображение, которое будет использоваться для сравнения с первым операндом - базовое изображение.
- Размер поиска
- Используется для задания области, где алгоритм будет искать локальную окрестность (на втором операнде). Должно быть больше, чем размер окна. Необходимо увеличить размер, если между сравниваемыми изображениями есть большие различия.
- Размер окна
- Используется для задания размера области локальной окрестности (на первом операнде). Должно быть меньше, чем размер поиска. Увеличение этого значения может улучшить работу модуля, но, разумеется, замедлит расчёт.
- Тип вывода
- Определяет выходной формат (пиксельного сдвига).
- Добавить маску порога низкой степени корреляции.
- Для некоторых пикселей (с не очень ярко выраженной окрестностью) степень корреляции будет низкой везде, но алгоритм всё равно будет выбирать некоторые максимальные значения этой степени. Чтобы увидеть эти точки и возможно убрать их из дальнейшего рассмотрения можно дать модулю установить маску сдвигов пикселей с низкой степенью корреляции, для которых вероятность того, что она определена правильно, невелика.

→ →
Этот модуль ищет заданный фрагмент внутри базового изображения. Он может генерировать изображение уровня корреляции или пометить результирующее положение фрагмента с помощью маски на базовом изображении.
- Ядро корреляции
- Изображение фрагмента которое нужно найти на базовом изображении. Размеры пикселя на обоих изображениях должны соответствовать друг другу.
- Использовать маску
- Если изображение фрагмента содержит маску, то можно включить эту опцию. Только пиксели под маской будут влиять тогда на результат поиска. Это может помочь для выделения фрагментов, которые имеют неправильную форму.
- Тип вывода
- Есть несколько вариантов того. что выводить: локальные максимумы корреляции (отдельные точки), маски с размером ядра для каждого максимума корреляции (хорошо подходят для презентаций) или просто степень корреляции.
- Метод корреляции
- Доступно несколько методов расчёта степени корреляции. Есть два основных класса. Для Корреляции корреляция рассчитывается интегрированием произведения базового изображения и изображения ядра. Для Разницы высоты корреляция рассчитывается как квадрат расстояния между базовым изображением и ядром (с последующей инверсией знака чтобы сделать более высокую оценку лучше). Для обоих методов область изображения, сравниваемая с ядром может использоваться как есть (необработанной), может быть выровнена до общего среднего значения или она может быть выровнена до общего среднего значения и нормализована до одинаковой суммы квадратов, дающих оценку.
- Порог
- Порог для определения, будет ли локальный максимум считаться «фрагмент найден здесь».
- Регуляризация
- Когда области базового изображения локально нормализуются, очень плоские области могут приводить к случайным соответствиям изображению фрагмента и другим странным результатам. Путём увеличения параметра регуляризации вклад плоских участков подавляется.
Обработку с помощью нейросети можно использовать для расчёта одного типа данных из другого даже если формула или соотношение, описывающие связь между ними, не описаны в явном виде. Соотношение непосредственно встраивается в нейросеть на этапе, называемом обучением, который задействует пары известных входных и выходных данных, обычно называемых модель и сигнал. В этом процессе сеть оптимизируется таким образом, чтобы воспроизводить настолько точно, насколько это возможно сигнал из модели. Обученная нейросеть затем может быть использована для обработки данных модели, для которых выходной сигнал не известен и получать, обычно несколько приближенно, как сигнал должен выглядеть. Другим возможным применением может быть аппроксимация методов обработки данных, которые являются точными, но требующими значительного времени. В этом случае сигналом будут выходные данные точного метода, и нейросеть обучается воспроизводить их.
Поскольку обучение нейросети и её применение это два совершенно различных шага, они реализованы в Gwyddion как две разные функции.
→ →
Основные функции, которые контролируют процесс обучения, содержатся во вкладке Обучение:
- Модель
- Данные модели, т.е. входные данные для обучения. Для обучения можно выбрать несколько моделей последовательно (с соответствующими сигналами).
- Сигнал
- Данные сигнала для обучения, т.е. выходные данные, которые должна выдавать обученная нейросеть. Изображение сигнала должно быть совместимо с изображением модели, т.е. иметь одинаковые размеры в пикселях и физические.
- Шагов тренировки
- Число шагов обучения, которое будет выполнено при нажатии . Каждый шаг состоит из одного прохода по всем данным сигнала. Можно установить число шагов обучения равным нулю, при этом обучения не будет производиться, но модель будет рассчитана нейросетью, и можно будет наблюдать результат расчёта.
- Начинает обучение. Это сравнительно медленный процесс, особенно при больших размерах поля данных и окна.
- Заново инициализирует нейросеть в необученном состоянии. Точнее, это означает, что веса нейронов устанавливаются в случайные значения.
- Режим использования маски
- Можно обучать нейросеть только на подмножестве сигнала, заданным маской на данных сигнала (использование маски на модели будет бессмысленным из-за размеров окна).
Параметры нейросети можно изменить на вкладке Параметры. Изменение как размеров окна, так и числа скрытых узлов означает переинициализацию неросети (как при нажатии кнопки ).
- Ширина окна
- Горизонтальный размер окна. Входные данные для сети состоят из области вокруг пикселя модели, называемой окном. Окно центрируется на пикселе, поэтому предпочтительными являются нечётные размеры.
- Высота окна
- Вертикальный размер окна.
- Скрытые узлы
- Число узлов в «скрытые» слое нейросети. Большее число узлов приводит к более универсальной сети, с другой стороны стороны, оно приводит к замедлению обучения и применения нейросети. Обычно это число является малым по сравнению с числом пикселей окна.
- Степень XY источника
- Степень, с которой единицы измерения пространственных размеров модели должны появляться в сигнале. Используется только при применении нейросети к данным.
- Степень Z источника
- Степень, с которой единицы измерения «высоты» модели должны появляться в сигнале. Используется только при применении нейросети к данным.
- Заданные единицы
- Фиксированные единицы измерения результата. Они комбинируются с другими параметрами единиц измерения, поэтому если вы хотите получить единицы измерения результата независимыми от входных, необходимо установить обе степени в ноль. Используются только при применении нейросети к данным.
Обученную нейросеть можно сохранить. загрузить для переобучения на других данных и т.п. Управление списком сетей похоже на предустановки загрузки сырых данных.
В дополнение к сетям в списке, существует ещё одна неназванная сеть, и это та сеть, которая обучается в текущий момент. Когда вы загружаете сеть, обучаемая сеть становится копией загруженной. Обучение затем не меняет именованные сети; чтобы сохранить сеть после обучения (под уже имеющимся или новым именем) необходимо явно использовать кнопку .
→ →
Применить обученную нейросеть просто: нужно выбрать одну из списка и нажать . Неименнованная сеть, которая обучается в настоящии момент также присутствует в списке под названием «Обучается».
Поскольку нейросети обрабатывают и производят нормализованные данные, они не сохраняют хорошо соотношения сторон, особенно если масштаб модели, использованной при обучении, сильно отличается от масштаба реальных входных данных. Если выходные данные должны масштабироваться вместе со входными, необходимо включить опцию Масштабировать пропорционально входным данным, которая масштабирует выходные данные пропорционально обратному отношению диапазонов текущих данных и данных, использованных при обучении.