На данный момент в Gwyddion доступны некоторые основные функции для визуализации объёмных данных и извлечения из них данных меньшей размерности (изображений, кривых). Также доступны несколько специализированных функций, нацеленных на обработку объёмных данных как массива кривых (или спектров) в каждой точке. Они представлены в меню окна инструментов.
Объёмные данные часто интерпретируются в Gwyddion как набор кривых, каждая из которых присоединена к одной точке плоскости xy, или, в альтернативном представлении как стек изображений вдоль оси z. Это означает, что функции работы с объёмными данными могут работать с осью z особым образом. Если вы собираетесь импортировать в Gwyddion объёмные данные с двумя пространственными осями и одной особой осью, делайте это так, чтобы особая ось соответствовала оси z.
Основные операции с объёмными данными включают в себя:
-

Меняет физические размеры, единицы измерения, масштаб значений, а также смещения в пространстве. Может оказаться полезным для корректировки необработанных данных, которые были импортированы с некорректными физическими масштабами или как простой способ заново откалибровать вручную размеры поля данных и масштаб значений.
-

Эта функция инвертирует знак всех значений в блоке объёмных данных.
Изображение предпросмотра для объёмных данных копируется в новое изображение в файле. Нередко такое же изображение, как изображение предпросмотра, можно получить с помощью модулей Вырезать или Характеризовать профили. Использование этих модулей даёт изображения с точно определёнными характеристиками. Однако, если вам просто нужно изображение предпросмотра, каким бы оно ни было, данная функция позволяет его получить.
-

Поскольку ось z трактуется несколько отлично от плоскости xy, иногда может оказаться полезно поменять местами роли осей. Данная функция поворачивает и зеркально инвертирует объемные данные таким образом, чтобы любая из текущих осей x, y и z могла стать выбранной осью в декартовых координатах для преобразованных данных.
Диалоговое окно обеспечивает, что преобразование будет невырожденным. Если попробовать получить преобразование, которое будет вырожденным, другая ось меняется таким образом, чтобы предотвратить вырождение. Другими словами, можно делать любую комбинацию зеркальных отражений и поворотов на углы, кратные прямому вокруг осей в декартовом пространстве.
Если объёмные данные содержат калибровку для оси z, и данная ось становится какой-то другой, то калибровка будет утеряна. Если такое происходит, показывается предупреждение.
-

В том случае, когда ось z не является пространственной, дискретизация вдоль неё может быть неравномерной, в отличие от осей построения изображения x и y, которые всегда имеют регулярные интервалы между значениями данных. В Gwyddion это представляется путём присоединения отдельного одномерного блока данных, связанного с осью z, который называется калибровкой Z.
Эта функция может показывать калибровку оси Z, удалить её, извлечь в виде кривой графика, перенести калибровку с других объёмных данных или присоединить новую калибровку из текстового файла. Для присоединения калибровки каждая строка файла должна содержать одно значение, задающее истинное значение zдля соответствующей плоскости, и, естественно, число строк файла должно соответствовать количеству плоскостей изображений в объёмных данных.

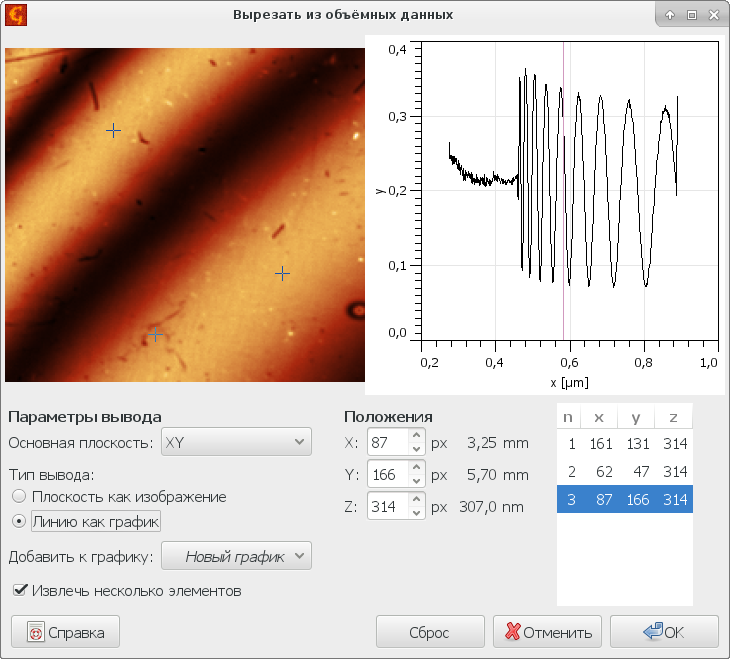
Профили вдоль каждой из осей и перпендикулярные любой из осей сечения в виде изображений можно извлечь из объёмных данных с помощью пункта меню → .
Изображение в выбранной плоскости сечения, именуемое Базовой плоскостью, всегда показывается в левой части и профиль вдоль перпендикулярной плоскости оси показывается в правой части диалогового окна. Можно изменить какой из профилей отображать перемещая выделенную точку по изображению. В обратную сторону это также работает, выбирая точку на графике профиля вы меняете положение плоскости сечения по этой оси. Также все три координаты, задающие положение плоскости и сечения можно ввести численно как X, Y и Z (в координатах пикселей).
Можно выбрать между извлечением изображений и профилей меняя тип вывода. Изменение этого параметра влияет на то, будет ли извлечено изображение слева или профиль справа после того, как пользователь нажмёт .
Также можно извлекать несколько профилей или плоскостей изображений одновременно. Если активирован пункт Извлечь несколько элементов, справа появится список выбранных точек. В этом случае тип вывода влияет на выбранное. В режиме Плоскость как изображение можно выбрать только одну точку на изображении (определяющую профиль, показываемый в окне графика), но несколько точек на графике, которые будут задавать по одной плоскости сечения каждая. И наоборот, в режиме Линия как график можно выбрать только одну точку на графике (задающую показываемую слева плоскость), но несколько точек на изображении, задающих места где будут извлечены профили.
Переключение между типами вывода при включенном выборе нескольких элементов уменьшает количество выбранных наборов координат до одного. Также можно использовать кнопку чтобы уменьшить выбор до одной точки, заданной по умолчанию, если вы хотите начать выбор заново.
Объёмные данные могут быть экспортированы в текстовый файл в нескольких различных форматах используя меню → . Возможные форматы вывода включают в себя
- Структурная сетка VTK
Формат, предназначенный для загрузки напрямую в программное обеспечение, основанное на VTK, такое, как ParaView. Значения сохраняются как блок
STRUCTURED_POINTS.- Один профиль вдоль Z на линию
Каждая строка выходного файла состоит из одного профиля вдоль оси z. Файл содержит столько строк, сколько точек в каждой плоскости xy (изображении) объёмных данных. Профили упорядочены сначала по строке, потом по колонке (обычный порядок для пикселей в изображении).
- Один слой XY на линию
Каждая строка выходного файла состоит из одной плоскости xy изображения, сохранённой в порядке сначала по строке. потом по столбцу (обычный порядок пикселей в изображении). В файле будет столько строк, сколько уровней z в объёмных данных. Слои сохраняются в порядке увеличения z.
- Матрицы, разделённые пустыми строками
Каждая строка выходного файла состоит из одной строки изобраения в одной плоскости xy. После того, как вся плоскость сохранена, пустая строка отделяет следующую плоскость. Слои опять же сохраняются в порядке увеличения z.

Основную характеризацию профилей вдоль оси z можно проводить используя меню → . Эта функция формирует изображение, образуемое значениями статистических характеристик профилей взятых вдоль оси z. Набор доступных статистических величин такой же, как и в инструменте статистики строк/столбцов.
Двойной выбор изображение/график обычно работает очень похоже на меню извлечения изображений и профилей. Основное отличие состоит в том, что на графике можно выбрать диапазон, определяя часть стека изображений, для которой будут рассчитываться статистические характеристики. Этот интервал также можно задать численно используя элементы ввода Диапазон.
Изображение слева показывает рассчитанные характеристики и отображает потенциальный результат работы модуля. Выбор другой точки на изображении меняет профиль, показываемый в окне графика, что может оказаться полезно для выбора подходящего диапазона. Значение для выбранного профиля показывается под управляющим элементом выбора статистической величины. Выбор профиля, однако, никоим образом не влияет на результат работы модуля.

Основную общую характеризацию плоскостей xy можно проводить используя меню → . Эта функция формирует график, образованный значениями статистических характеристик отдельных плоскостей xy объёмных данных или их фрагментов. Набор доступных статистических величин является подмножеством тех, что доступны в инструменте расчёта статистических величин. Для некоторых величин может потребоваться какое-то время, чтобы рассчитать их для всех слоёв.
Двойной выбор изображение/график обычно работает очень похоже на меню извлечения изображений и профилей. Основное отличие состоит в том, что на плоскости изображения можно выбрать прямоугольную область, для которой будут рассчитываться статистические характеристики. Этот прмоугольник также можно задать численно используя элементы управления Начало и Размер.
График справа показывает рассчитанные характеристики и отображает потенциальный результат работы модуля. Выбор другой точки на графике меняет плоскость xy показываемую в окне изображения, что может быть полезно для выбора подходящей области. Значение для выбранной плоскости показывается под управляющим элементом выбора статистической величины. Однако, выбор плоскости никоим образом не влияет на результат работы модуля.
Арифметика на объёмных данных работает точно таким же образом, как арифметика для изображений, и использует тот же синтаксис выражений.
Изображение предпросмотра показывает усреднение по всем уровням, набор автоматически установленных переменных слегка отличается:
| Переменная | Описание |
|---|---|
d1, …, d8 | Значение данных в вокселе. Значение показывается в базовых физических величинах, т.е. для тока в 15 нА, значение d1 будет 1.5e-8. |
x | Горизонтальная координата вокселя (в физических величинах). Будет одинаковой для всех объёмных данных из-за требований совместимости. |
y | Вертикальная координата вокселя (в физических величинах). Будет одинаковой для всех объёмных данных из-за требований совместимости. |
z | Координата глубины (уровня) вокселя (в физических величинах). Будет одинаковой для всех объёмных данных из-за требований совместимости. |
zcal | Координата калибровки z вокселя (в физических величинах) если объёмные данные содержат калибровку оси z (См. Калибровки оси Z). |


Техники сканирующей спектроскопии, такие как измерение кривых сила-расстояние в количественной нанометрологии (QNM), измерение вольтамперных характеристик в полупроводниковой промышленности, спектроскопия комбинационного рассеяния в характеризации новых материалов требуют снятия спектра в каждой точки сетки, наложенной на поверхность образца. Работа с полученным массивом данных является затруднительной, поскольку приходится работать и анализировать тысячи спектров. Если интересующий образец содержит ограниченный набор областей с очень похожими спектрами в каждой области, то техники, позволяющие группировать похожие спектры вместе, будут весьма полезны. Одним из подходов к решению подобной задачи является кластерный анализ. В программе Gwyddion на данный момент реализованы два метода: K-средних и K-срединных.
Оба алгоритма разработаны чтобы найти K кластеров с похожими друг на друга спектрами внутри кластера и максимально различными между кластерами. Таким образом, параметр количество кластеров определяет число кластеров K которое нужно получить в результате работы. Настройки знаков точности сходимости и макс. число шагов задают критерии сходимости алгоритма, который останавливается либо если достигнута заданная точность положения центров кластеров, либо превышено максимальное число итераций. Большая точность требует большего числа итераций, лимит на число циклов останавливает алгоритм, попавший в бесконечный цикл, если заданная точность не может быть достигнута.
Опция нормализовать это в некотором роде экспериментальная методика, которая приводит к более удачным результатам для данных сканирующей спектроскопии. Если интенсивность спектра не является важной и вы хотите группировать данные по похожести спектральных особенностей в средней частотной области (что является типичным, например, для спектроскопии комбинационного рассеяния), то включите этот флажок. Эта опция убирает низкочастотный фон спектра путём вычитания минимального значения в скользящем окне, и затем нормализует спектр, делая среднюю интенсивность равной 1.0. Оба модуля выводят два поля данных: одно показывает к какому кластеру принадлежит каждый спектр в точке и второй показывает ошибку — разницу между текущим спектром и центром кластера, к которому он принадлежит. Если включена нормализация, то третье выводимое поле данных показывает значения, на которые делились интенсивности спектральных линий (после вычета низкочастотного фона). Также выводится график со спектрами, соответствующими центрам кластеров.
Алгоритмы, лежащие в основе этих двух модулей основаны на кластеризации методами машинного обучения: соответственно, K-средних и K-срединных. Мы считаем каждый спектр (график, извлекаемый из объёмных данных вдоль оси z) точкой в многомерном пространстве, размерность которого соответствует числу точек в графике. расстояние между парой точек определяется как квадратный корень из суммы квадратов разностей координат в каждой спектральной точке-измерении (L2-норма). Оба алгоритма инициализируются случайным выбором K точек из имеющегося набора спектров в качестве центров кластеров. Затем применяется обычный двухстадийный алгоритм: мы распределяем каждую точку по кластерам таким образом, чтобы она принадлежала к кластеру, центр которого будет ближе всего к ней, и затем перемещаем центры кластеров. Разница двух аллгоритмов состоит в том, как рассчитать новые положения центров кластеров: они будут средним значением координат точек, принадлежащих кластеру, для K-средник и срединным вдоль каждого направления в многомерном пространстве для K-срединных. Результаты последней итерации возвращаются в основную программу в формате, описанном выше.
Удалить выпадающие для модуля K-средних изменяет алгоритм расчёта центров кластеров таким образом, чтобы использовать точки, лежащие не дальше значения Порога выпадающего умноженного на среднеквадратичное отклонение данных σ внутри каждого кластера. Эта опция удаляет отдельные выпадающие дефективные точки (выбросы, космические лучи на изображениях микроскопии комбинационного рассеяния и т.д.) из расчёта, делая центры кластеров несколько более чистыми и раздельными. Также эта опция может перемещать границу между близко расположенными кластерами к более корректному положению между двумя центрами максимальной плотности точек, не испорченному выпадающими далёкими от центра точками.
Некоторые из функций работы с объёмными данными предназначены для обработки данных МСМ. Они обычно в целом аналогичны их эквивалентам для изображений.
Преобразование данных МСМ в градиент силы полностью одинаково для объёмных данных и изображений. Следовательно, общие сведения о преобразовании данных МСМ для изображений применимо без изменений и для объёмных данных.
Оценка передаточной функции → также достаточно похоже на оценку передаточной функции для изображений. Передаточная функция оценивается для каждого уровня объёмных данных и её различные значения строятся в виде графиков. Какие из графиков будут отображаться выбирается на вкладке Параметры вывода. Параметр регуляризации σ может быть одинаковым для всех уровней или он можем оцениваться отдельно для каждого путём выбора опции Оценивать параметр регуляризации для каждого уровня. расчёт в этом случае будет идти заметно дольше. Для метода Наименьших квадратов даже размер передаточной функции может быть оценен отдельно для каждого уровня если включено Оценивать размер для каждого уровня. Размер, заданный в диалоговом окне приме этом определяет размер вывода - и, следовательно, максимальный возможный размер. Более маленькие передаточные функции при этом дополняются нулями до заданного размера.
Проверка соответствия поля утечки → пересчитывает поле для разных высот аналогично Сдвигу поля МСМ. Однако, поскольку объёмные данные содержат изображения, соответствующие многим различным уровням, возможно рассчитать поле для каждого и сравнить с рассчитанным полем. Это данный модуль и делает.