Gwyddion currently provides several basic functions for visualisation of volume data and extraction of lower-dimensional data (images, curves) from them. A few specialised functions, focused on processing volume data as curves (or spectra) in each pixel, are also available. They are all present in the menu of the toolbox.
Volume data are often interpreted in Gwyddion as a set of curves, each attached to one pixel in the xy plane, or alternately stack of images along the z axis. This means the volume data functions may treat the z axis specially. If you intend to import volume data with two spatial and one special dimensions to Gwyddion make sure that the special axis corresponds to z.
Elementary operations with volume data include:
-

It changes the physical dimensions, units or value scales and also lateral offsets. This is useful to correct raw data that have been imported with wrong physical scales or as a simple manual recalibration of dimensions and values.
-

This function inverts the signs of all values in the volume data.
The preview image of the volume data is copied to a new image in the file. Frequently the preview is an image that could be equivalently obtained using Cut and Slice or Summarize Profiles. And using these functions create images of well-defined quantities. However, if you simply want to get the preview image, whatever it happens to be, this function will do just that.
-

Since the z axis is treated somewhat differently than the xy plane, it can be useful to change the roles of the axes. This function rotates and/or mirrors the volume data so that any of the current x, y and z axes will become any chosen Cartesian axis in the transformed data.
The dialogue ensures the transformation is non-degenerate. When you select a transformation that would be degenerate, another axis is adjusted to prevent this. Otherwise, you can perform any combination of mirroring and rotations by multiples of 90 degrees around Cartesian axes.
If the volume data have a z-axis calibration and z becomes some other axis the calibration will be lost. A warning is shown when this occurs.
-

When the z-axis is non-spatial the sampling along it may be sometimes irregular, unlike the imaging axes x and y that are always regular. In Gwyddion this is represented by associating certain one-dimensional data with the z-axis, called the Z calibration.
This function can display the Z calibration, remove it, extract it as a graph curve, take calibration from another volume data or attach a new calibration from a text file. For attaching a calibration, each line of the file must contain one value specifying the true z-axis value for the corresponding plane and, of course, the number of lines must correspond to the number of image planes in the volume data.

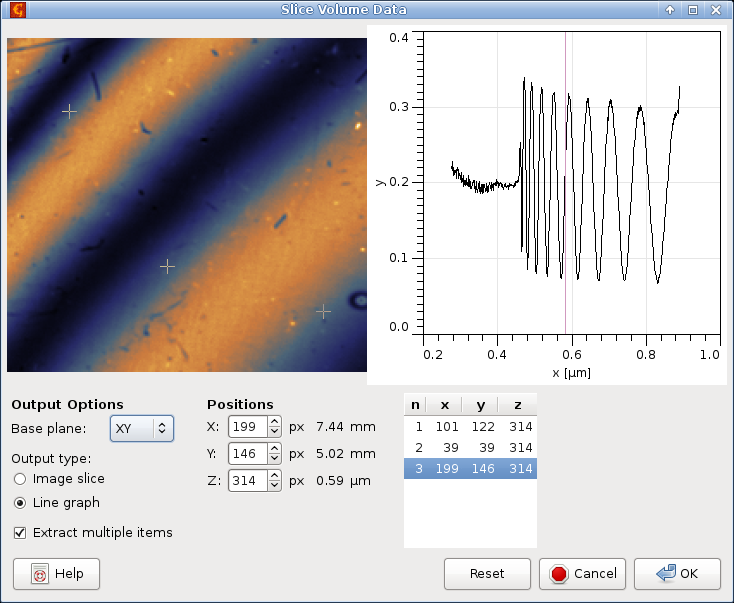
Profiles along any axis and image slices in planes orthogonal to any axis can be extracted with → .
The image slice in the selected plane, called Base plane, is always shown in the left part and the profile along the remaining orthogonal axis is shown in the right part of the dialogue. You can change the where the line profile is taken by moving the selected point in the image. Conversely, the image plane location can be moved by selecting a point in the profile graph. Both can be also entered numerically as X, Y and Z (in pixel coordinates).
You can choose between image and profile extraction freely by changing Output type. Changing the output type only influences whether the module creates the image on the left or the profile graph on the right when you press .
It is also possible to take multiple profiles or image slices at the same time. If Extract multiple items is enabled a list of selected points will appear on the right. In this case the output type influences the selection. In the Image slice mode you can select only one point in the image (determining the profile shown in the graph) but multiple points in the graph, each determining one output image plane. Conversely, in the Line graph mode you can select only one point in the graph (determining the image plane shown) but multiple points in the image, determining where the line profiles will be taken.
Switching betwen the output types when mutli-item extraction is enabled reduces the selected coordinate set to a single point. You can also use the button to reduce the selection to the default single point if you want to start afresh.
Volume data can be exported to text files in several formats using → . The possible output formats are
- VTK structured grid
Format indented for direct loading into VTK-based software such as ParaView. The values are dumped as a block of
STRUCTURED_POINTS.- One Z-profile per line
Each line of the output file consists of one z-profile. There are as many lines as there are points in each xy plane (image) of the volume data. The profiles are ordered by row, then by column (the usual order for image pixels).
- One XY-layer per line
Each line of the output file consists of one xy image plane, stored by row, then by column (the usual order for image pixels). There are as many lines as there are z-levels in the volume data. The layers are stored in order of increasing z.
- Blank line separated matrices
Each line of the output file consists of one image row in one xy plane. After one entire plane is stored a blank line separates the next plane. The layers again stored in order of increasing z.

Basic overall characterisation of profiles along the z-axis can be performed using → . This function creates an image formed by statistical characteristics of profiles taken along the z-axis. The set of available statistical quantities is the same as in the Row/column statistics tool.
The dual image/graph selection generally works very similarly to Image and profile extractions. The main difference is that an interval can be selected in the graph, defining the part of the image stack from which the statistical characteristics will be calculated. The interval can be also entered numerically using the Range entries.
The image on the left shows the calculated characteristics and corresponds to the output of the module. Selecting a different point in the image changes the profile displayed in the graph, which can be useful for choosing a suitable range. The value for the selected profile is displayed below the statistical quantity selector. However, choosing a profile does not influence the output in any way.

Basic overall characterisation of xy planes can be performed using → . This function creates a graph formed by statistical characteristics of individual xy-planes in the volume data or their parts. The set of available quantities is a subset of those calculated by Statistical quantities tool. A few quantities can take some time to calculate for all layers.
The dual image/graph selection generally works very similarly to Image and profile extractions. The main difference is that a rectangular region can be selected in the image plane, defining a rectangle from which the statistical characteristics will be calculated. The rectangle can be also entered numerically using the Origin and Size controls.
The graph on the right shows the calculated characteristics and corresponds to the output of the module. Selecting a different position in the graph changes the xy plane displayed in the image, which can be useful for choosing a suitable region. The value for the selected plane is displayed below the statistical quantity selector. However, choosing a plane does not influence the output in any way.
Arithmetic with volume data works exactly the same as image data arithmetic, including the same expression syntax.
The preview shows the average over all levels and the set of automatic variables is slightly different:
| Variable | Description |
|---|---|
d1, …, d8 |
Data value at the voxel. The value is in base physical units,
e.g. for current of 15 nA, the value of d1
is 1.5e-8.
|
x | Horizontal coordinate of the voxel (in real units). It is the same in all volume data due to the compatibility requirement. |
y | Vertical coordinate of the voxel (in real units). It is the same in all volume data due to the compatibility requirement. |
z | Depth (level) coordinate of the voxel (in real units). It is the same in all volume data due to the compatibility requirement. |
zcal | Calibrated z-coordinate of the voxel (in real units) if the volume data have z-axis calibration (see Z calibrations). |


Techniques of imaging spectroscopy like F-D in QNM (Quantitative Nanomechanical Mapping) applications, I-V in semiconductor engineering, Raman in material characterization require to measure spectrum per each point of data grid on sample surface. Working with obtained array is not so simple, as we need to work with thousands of spectra and analyze each of them. If the sample of interest has limited number of regions with very similar spectra inside each region, some technique grouping similar spectra together can be of great help. One possible way of doing so is using clustering analysis. In Gwyddion currently two methods is implemented: K-means and K-medians.
Both algorithms are intended to find K clusters with similar spectra inside the cluster and maximally different between clusters. So Number of clusters is how many clusters K you want to obtain in the result. Convergence precision digits and Max. iterations regulate convergence criteria of algorithms that stop either if required precision of cluster centers position is achieved or allowed number of convergence cycles is exceeded. Higher precision require more steps to achieve, second limit is mostly intended to get rid of endless loops if the precision is to high for this set of data.
Normalize is somewhat experimental technique that qives nice results for imaging spectroscopy. If you are not interested in spectral intensities and want to cluster data by similarity of middle-frequencies of spectral features (it is typical, for example, for Raman microscopy), than enable this checkbox. It removes low frequency background by substraction of minimum withing the moving window, and then normalizes spectrum to make average intensity be equal 1.0. Both modules outputs two datafields: one shows to which cluster belongs the current spectrum, another shows error — difference between the current spectrum and center of corresponding cluster. If normalization is enabled than third datafield shows values the spectral intensities was divided by during normalization (after low-freq. filtering). Also graph with spectra corresponding to the centers of clusters is extracted.
Algorithms beside this two modules are based on usual unsupervized learning clustering: K-means and K-medians, correspondingly. We consider each spectrum (graph extracted along z-axis) to be the point in multidimensial space with the number of dimensions equal number of data point in the graph. We define distance between points as square root from sum of squared differencies along each direction (L2-norm). Than we initialize both algorithms by choosing random K points from the volume data as cluster centers. Than the usual two step algorithm is applied: we assign each point to the cluster whose center is nearest to the point and then move centers of the clusters. The difference between two modules is how to calculate the cluster center: it is mean value of cluster points for K-means and median along each direction for K-medians. The results from the last iteration are returned back to the program.
Remove outliers for K-means modifies algorithm for calculation of cluster centers to include only datapoints within Outliers threshold multiplied by data variation σ for each cluster. It removes single distinct bogus data points (like spikes, cosmic rays in Raman spectroscopy and so on) from calculation, making cluster centers somewhere more clean and distinct and also can shift border between intermixing clusters to more correct place between two centers of maximal point densities not disturbed by far outliers.
A few volume data functions are dedicated to MFM data processing. They are generally analogous to their image counterparts.
Conversion of MFM data to force gradient is exactly the same for volume and image data. Therefore, the summary of image MFM data conversion applies to volume data unchanged.
The transfer function estimation → is also quite similar to image transfer function estimation. The TF is estimated for each level in the volume data and its various properties plotted as graphs. Which graphs are plotted can be selected in the Output Options tab. The regularisation parameter σ can be the same for all levels, or it can be estimated for each level by enabling Estimate sigma for each level. The computation then takes notably longer. For the Least squares method, even the transfer function size can be estimated for each level when Estimate size for each level is enabled. The size given in the dialogue then determines the size of the output – and thus maximum possible size. Smaller transfer functions are extended with zeros to this size.
The stray field consistency check → recalculates the field to a different height similarly to MFM field shift. However, since the volume data contains images corresponding to many different levels, it is possible to calculate the field for each and compare it to the calculated field. And this is what the module does.